One of the fundamental differences between an Excel spreadsheet and a Microsoft Access or SQL Server database is the database’s ability to group data by subject into tables and create links between that information. This type of organization enables the user to store large amounts of data and retrieve specific information quickly by writing queries that will search on the various fields. Referential Integrity is actually a simple but essential concept to understanding how databases like Access or SQL Server work. Once you understand it, you will be able to use these tools to better organize and report on your data.
To demonstrate this concept, I’m going to use a few tables in a Microsoft Access database. Access is a great environment to start learning about databases as it provides a user-friendly interface and is widely available through Office365.
Watch the companion video for this article on YouTube or continue article below …
Example: Books and Authors
Let’s say that you have a small library that you want to catalog. It probably consists of mostly books and periodicals but you might have some multimedia, too. You could put everything in one giant spreadsheet but you’ll eventually find yourself repeating a lot of information such as author and publisher information that’s common to a lot of different items.
Repetition is a problem when organizing data because every time you repeat a piece of information, two things happen: it takes up more space and you run the risk of it being repeated incorrectly. The second item is especially bad because it makes it difficult to find specific information when you need it. If an author’s name is misspelled, a search on the correct spelling or a different representation of his name (i.e. Robert Heinlein vs. Heinlein, Robert) will not find all of the records you need.
This why relational databases like Access and SQL Server break information down into subject tables in order to ensure that each bit of information can be stored once and then referenced as needed. The technical name for these subjects is entities and tables are one representation of these entities.
Creating the Tables
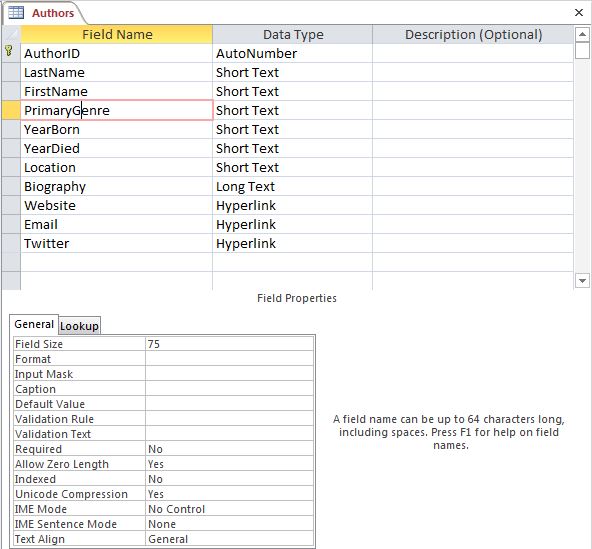
When building the database, the two obvious entities to be represented are books (or media) and authors. In the screenshot to the left, you can see the Access table design view for an Authors table that includes such information as the author’s name, biography and contact information. This information is stored in fields which represent the different attributes of the entity. You would not want to repeat all of this information each time you stored another of the author’s books but since it’s in a separate table, each author can have their own row and the information can be written once and updated as needed. This is technically possible in Excel with different tabs but Excel does not offer some of the capabilities you’ll see in a moment.
Earlier, I referred to Access as a relational database. The reason it’s called relational is because data is grouped into tables like this one which are also called relations. In a well-designed database, each field within the table is supposed to relate to the subject of the table.
If you’ve looked at the screenshot, you’ll notice a field at the top of the table definition called AuthorID and you’ll notice that the Data Type listed next to it is AutoNumber. The AuthorID field is what’s referred to as a Primary Key. This is a field that serves to identify each row in a table so that it can be referenced by other tables and the information within it can be used. The data type assigned to it determines how the field will represent the data and what rules will be applied to it.
In Access, an AutoNumber field automatically assigns a unique number for every record entered into the table. You can see this in the screenshot of the authors table below where a few records have been entered. This is also referred to as an identity field and is often used to create an automatic primary key.
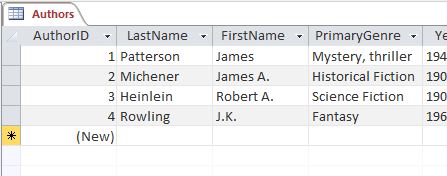
You might ask at this point “What if the same author is entered into multiple rows? How does the primary key ensure that each row is unique?” The answer is that it doesn’t; it just provides an identifier. It is up to whoever develops the database to put in additional controls to ensure that the same information is not entered twice. This can include setting other fields or field combinations to be unique and making sure that whatever forms are included have enough search functions to enable the users to quickly determine if information is already there before entering it again.
Linking to the Data
Now that we have an authors table, we need another table to contain the information about the books these authors have written.

In our example, there’s now another table called PublishedWorks which can hold the information for each book, article or other publication by an author. This table has its own primary key but it also includes a field called “Author” and you’ll notice the data type is set to a number. This is because the field needs to hold the correct value to indicate which author the book belongs to. In this way, the database can link back to that data without having to repeat it. Also, if the data changes, for example if an author creates a Twitter account or website, that data can be changed in one place and whatever form or report is displaying the information for that author can reflect that change. The Author field is referred to as a foreign key because it is referencing a primary key from another table.
Once I add some data to the new table, you’ll see a little better how this works.
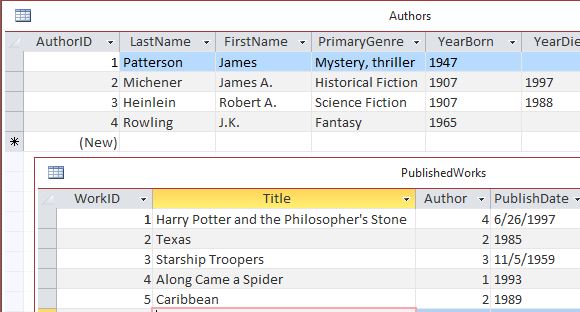
You’ll notice that the numbers in the Author field are not unique. That’s fine because each author can and probably will have more than one book. This is called a one-to-many relationship; one author to many books. The relationship between the tables is also referred to as a parent-child relationship with Authors supplying the primary key value as the parent.
At this point, you’re probably thinking that it seems really complicated to have to remember these numbers instead of author names but, in fact, you don’t. Again, whatever forms and reports are included in the database are designed to make use of this referencing relationship between the tables. The correct number for each author is then automatically added to the PublishedWorks table for each publication is added.
Referential Integrity
This is where referential integrity comes into the picture. Relational databases allow for relationships to be defined and remembered for the type of reference shown above. Normally this would be done before any data is added. The image below shows an example of this from the Relationships window in Microsoft Access where a relationship is being created between the Authors and PublishedWorks tables.
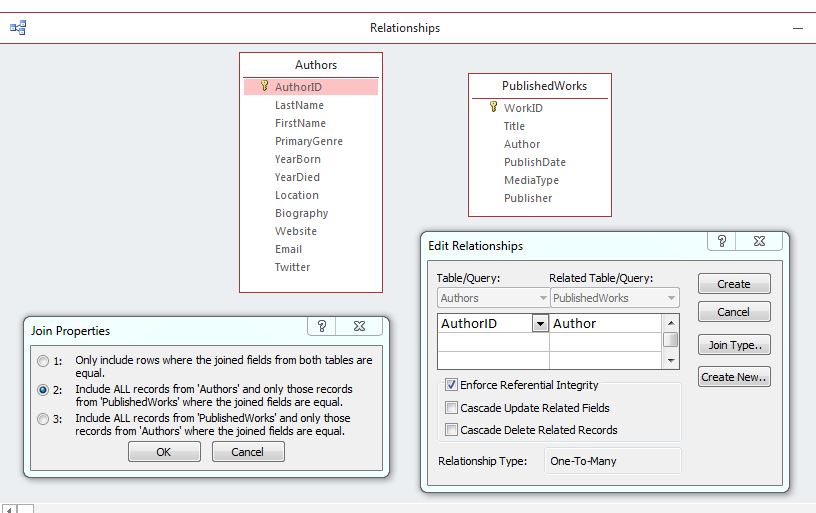
In the bottom-right corner of the image, you can see the Edit Relationships panel which lists the two tables and their corresponding keys (primary and foreign). It also has a checkbox for the Referential Integrity settings.
Referential Integrity means that the database will not allow actions that result in a table with a foreign key (PublishedWorks) to contain foreign key values that are not found in the table with the primary key (Authors). These records would be called orphaned records as they had no parent record in Authors.
- A record in the Authors table that is referenced by records in PublishedWorks (i.e. J.K. Rowling) cannot be deleted.
- New records in PublishedWorks must reference an existing value in the AuthorID field in Authors.
These restrictions are in place once the Referential Integrity checkbox is checked and the relationship is created. The completed relationship is shown below.

This relationship will now be enforced by Microsoft Access for any query, form or report that works with these two tables.
Exceptions
With no extra instructions, referential integrity would cause a message like this one to appear if I tried to delete a record in Authors that was referenced in PublishedWorks.

In the Edit Relationships box above, you might also notice a couple of extra options – Cascade Update Related Fields and Cascade Delete Related Fields. These options allow the database to handle situations where the primary key record needs to be deleted or the primary key value itself needs to be changed. (Sometimes database developers use real-world values for primary keys.)
- Cascade Delete will delete any records in PublishedWorks that reference a record in Authors that was being deleted, after a warning message. With this option, you could remove an author and all of his or her books from the database.
- Cascade Update will update the foreign key value in any PublishedWorks records that reference a primary key value in Authors. In other words, if I was using the author’s e-mail as the primary key and that e-mail changed in Authors, it would be updated in all the PublishedWorks records.
What Does this Mean in the Real World?
This will probably seem pretty obscure and technical to you until you understand how the users see it. Databases on their own aren’t really useful unless you can search and report on the data in various ways. Access and other systems enable you to create data entry forms and finished reports to work with the information in the databases. The image below shows the query interface in Access that enables you to specify the data you want to see at a specific time.

The query automatically recognizes the relationship between these tables. In the bottom half of the query, you can see specific fields have been selected from both tables and the query has been instructed to sort on the book title. The results are shown below.
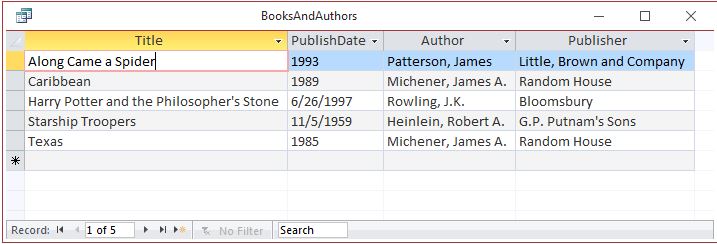
This query has assembled a report-ready collection of data from two related tables. The author first and last names are stored in separate fields but have been formatted to appear as a single value. This means that you could display them with the first name first but still sort on last name. James A. Michener appears twice in the results but his name is only stored once in the database and, no matter how many of his books are included, his name will always be correct because it’s only being referenced from one entry. This data can be reformatted and displayed in any way it’s needed.
What Does this Mean for You?
Once you understand referential integrity, you are better able to understand the role of database systems such as Microsoft Access or MySQL which are frequently used for such things as reporting systems and website data storage. This enables you to learn about these tools and put them to work on large collections of data and that’s a very valuable skill in business.
Find related products on Amazon.com ...

Integrity - Doing the Right Thing Even When No One is Watching - New Motivational POSTER
$10.99 (as of April 16, 2024 23:59 GMT -04:00 - More infoProduct prices and availability are accurate as of the date/time indicated and are subject to change. Any price and availability information displayed on [relevant Amazon Site(s), as applicable] at the time of purchase will apply to the purchase of this product.)
